

Bottom Line Up Front: This post outlines six powerful workflow patterns in Tilebox, from processing data directly in-orbit to cut downlink costs, to building on-demand data products for your customers. Whether you're developing algorithms, operating in near real-time, or automating routine tasks, these examples demonstrate how to transform raw geospatial data into actionable intelligence more efficiently.
Your main focus is on delivering products and insights. Tilebox gives you the power to do that, and without frustrating limitations. We’ve compiled a list of our most useful workflow types with examples to help you improve your current processes. Learn how to scale up, expedite, and diversify your products and services to transform raw geospatial data into actionable intelligence.
In-Orbit Workflows: Process Data at the Edge
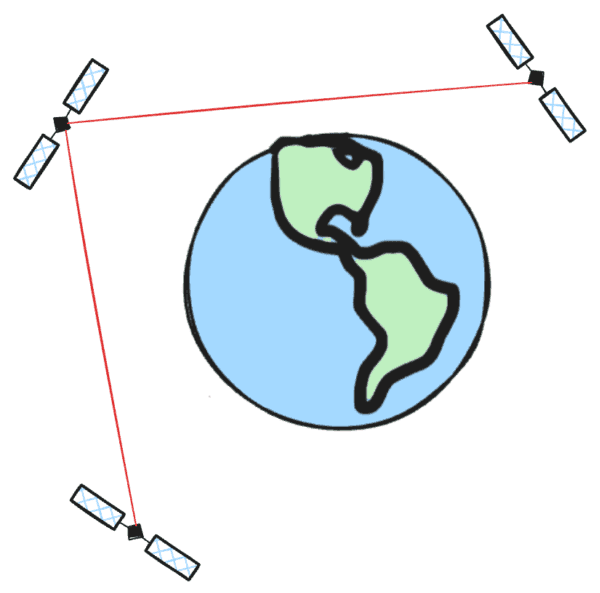
Downlinking raw satellite data is like shipping ore from a mine; it’s bulky and expensive. Processing it in-orbit is like refining it at the source and shipping only the gold. This approach dramatically reduces downlink costs, a substantial part of satellite operations.
For monitoring use cases requiring extremely low latency, or for hyperspectral providers who need to downlink only specific bands, on-orbit processing is a necessity. It moves beyond simple object detection demos to enable operational, decision-making AI in space.
Tilebox Highlights:
Lightweight and Efficient: Tilebox is designed to be resource-efficient, consuming minimal power and compute from precious on-orbit resources. Work can be queued and executed only when compute capacity is available, allowing modules to be scaled up or down to fulfill power budgets.
Ground-to-Space API Parity: The same APIs for workflow orchestration and management are used on-orbit and on the ground. This allows you to create a "digital twin" of your on-orbit processing state for rapid testing, validation, and iteration of algorithms on the ground before uplinking.
Integrated Observability for Attribution: Collect critical attribution data and logs from in-orbit processes. This provides a tight feedback loop with ground operations, which is essential for operationalizing AI and decision-making in space.
Parallel Processing in Space: Fully utilize on-orbit compute capabilities by running tasks in parallel, ensuring that you get the most out of your hardware.
What you’ll need:
On-orbit compute hardware with Tilebox deployed (c.f. from one of our pre-integrated compute module partners).
A ground-based environment for algorithm development and testing.
Next Steps:
Start developing your algorithms on the hosted version of Tilebox today; they will be fully compatible with the on-board daemon.
Contact our team to discuss how to implement Tilebox for your on-orbit processing needs.
Distributed Workflows: Process Data Across Multiple Environments
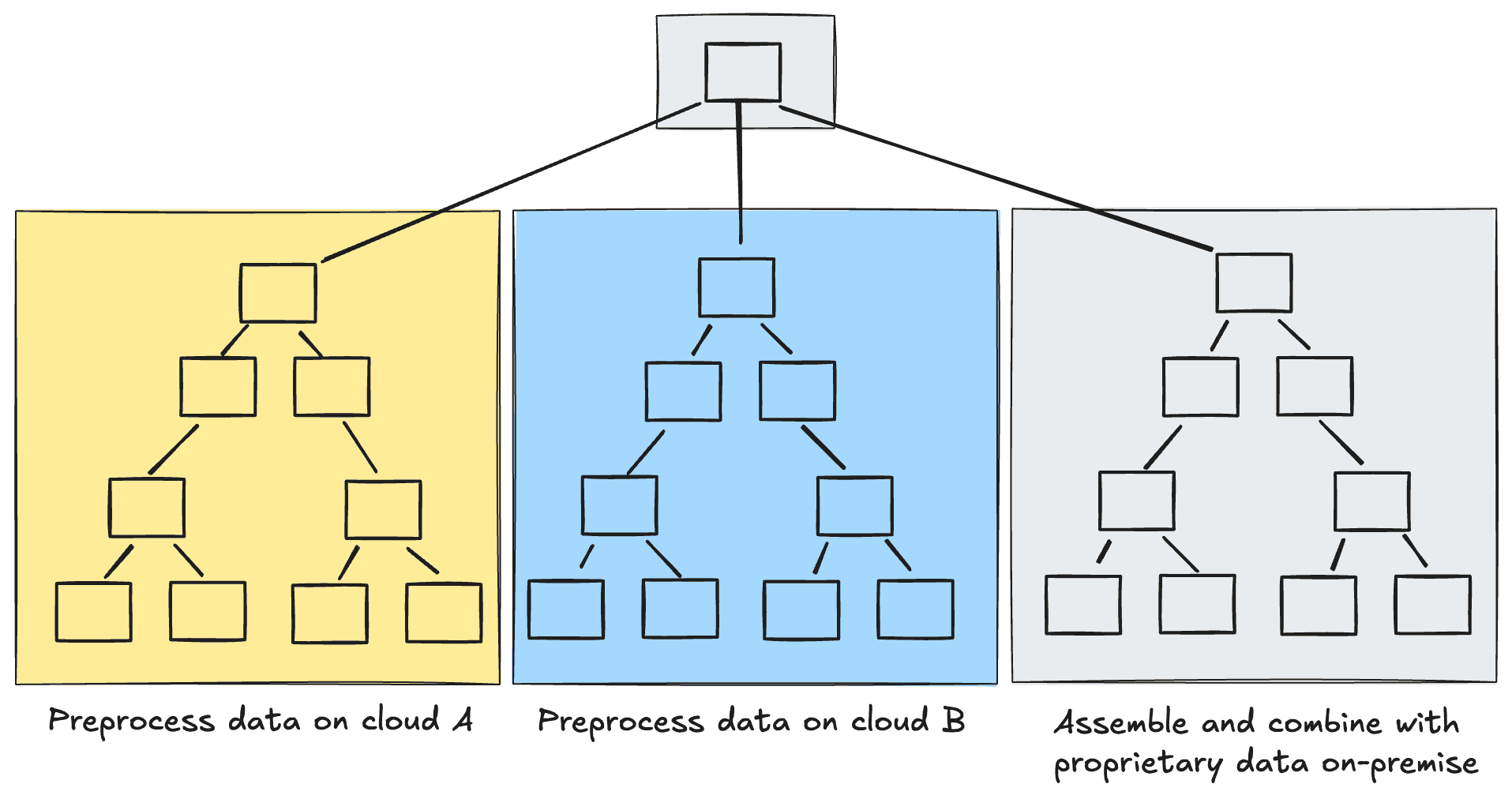
As remote sensing data is often distributed across various locations, workflows that span multiple clouds and on-premise compute environments are becoming increasingly common. Tilebox simplifies the implementation of these complex workflows, such as data fusion use-cases like wildfire detection using both Landsat and Sentinel data. All workflows may be distributed.
Tilebox Highlights:
Process Data at the Source: Minimize costly data egress fees and reduce latency by running compute tasks directly where your data resides, whether on-premise or across multiple cloud providers.
Natively Heterogeneous: Orchestrate workflows that span on-premise servers, multiple public clouds, and even on-orbit compute, without requiring complex Kubernetes setups.
Utilize Specialized Hardware: Route specific tasks to clusters with specialized hardware, such as GPUs or high-memory nodes, ensuring optimal performance for every step of your pipeline.
Simplified Multi-Cluster Dependencies: Declare dependencies between tasks in different environments as easily as if they were on the same machine. Tilebox handles the complex orchestration.
Resilience Across Environments: The failure of a node in one environment doesn't cascade. The workflow's built-in fault tolerance ensures that the overall process can continue even with localized infrastructure issues.
What you’ll need:
Access to two or more distinct compute environments (e.g., on-premise and public cloud).
Tilebox Task Runners deployed in each of these environments.
Tasks designed to run in specific environments, orchestrated via Tilebox Clusters.
Next Steps:
Read about how to manage clusters for distributed workflows.
Create a cluster in the console
Start two runners, one in each cluster
Schedule work from a task running on one cluster to the other
Near Real-Time Workflows: Trigger Processing on Incoming Data
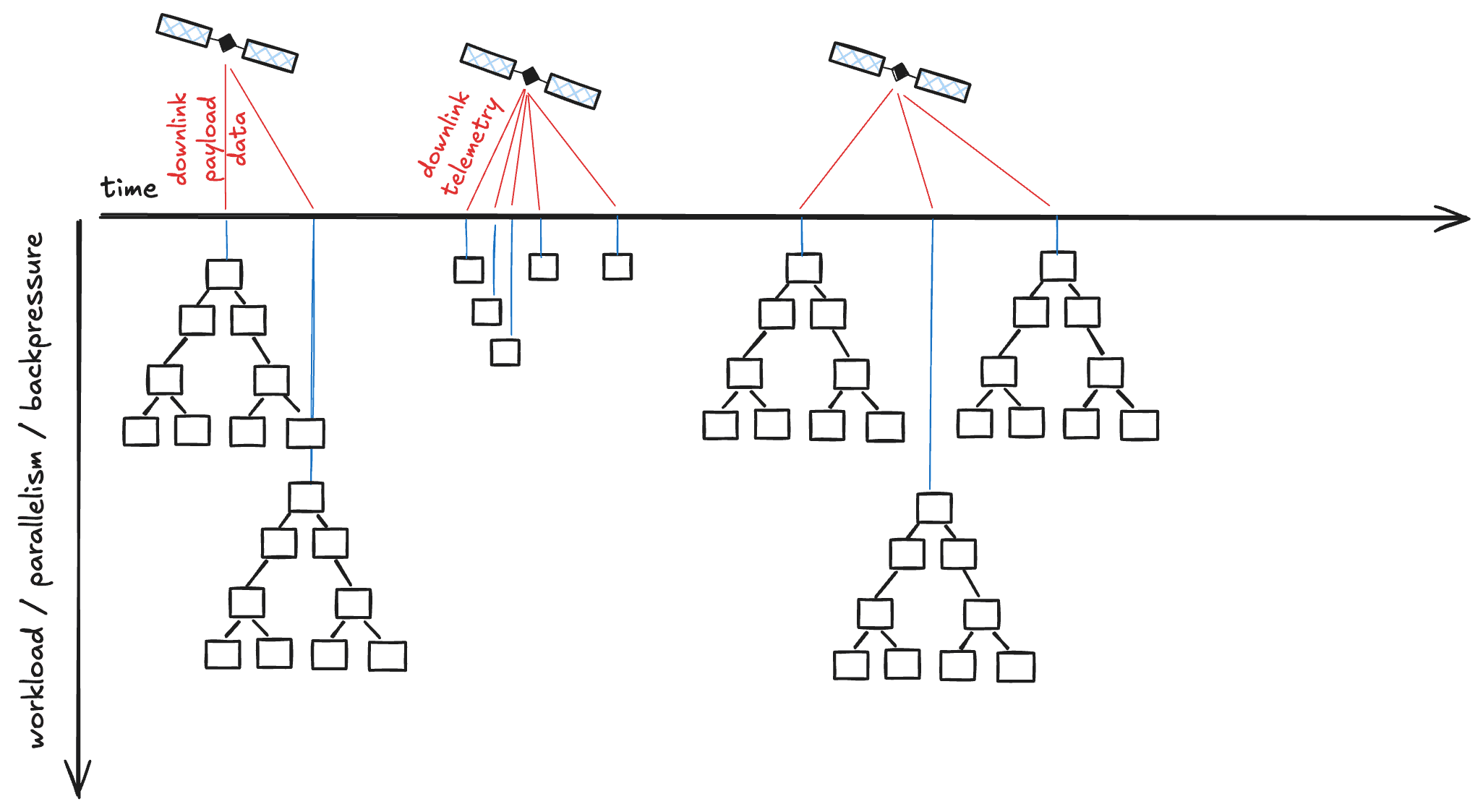
When speed is critical, workflows can be triggered in near real-time as new data becomes available. This is necessary for applications like wildfire detection or maritime surveillance, which require immediate processing of newly published data.
For instance, when a satellite downlinks new payload data, it can automatically trigger the L0 to L1 processing chain.
Tilebox Highlights:
Low-Overhead Processing: The time it takes to start a task is in the millisecond range, making Tilebox highly effective for latency-sensitive applications with frequent, small workloads.
Diverse Triggering Mechanisms: Initiate workflows automatically from a variety of sources, including Storage Events in cloud buckets (GCS, S3) and local file systems (both in closed beta)
Robust Backpressure Management: Gracefully handles sudden bursts of trigger events, ensuring system stability and preventing your infrastructure from being overloaded during data storms.
Full Observability: Monitor the health and performance of your automated pipelines with integrated Tracing and Logging, which is essential for production environments.
What you’ll need:
An event source configured to trigger workflows (e.g., a cloud storage bucket with notifications enabled).
A Task defined to handle the incoming event data.
A continuously running Tilebox Task Runner listening for these jobs.
Next Steps:
Learn how to set up automations to trigger workflows from events.
Customer-Triggered Workflows: Enable On-Demand Processing
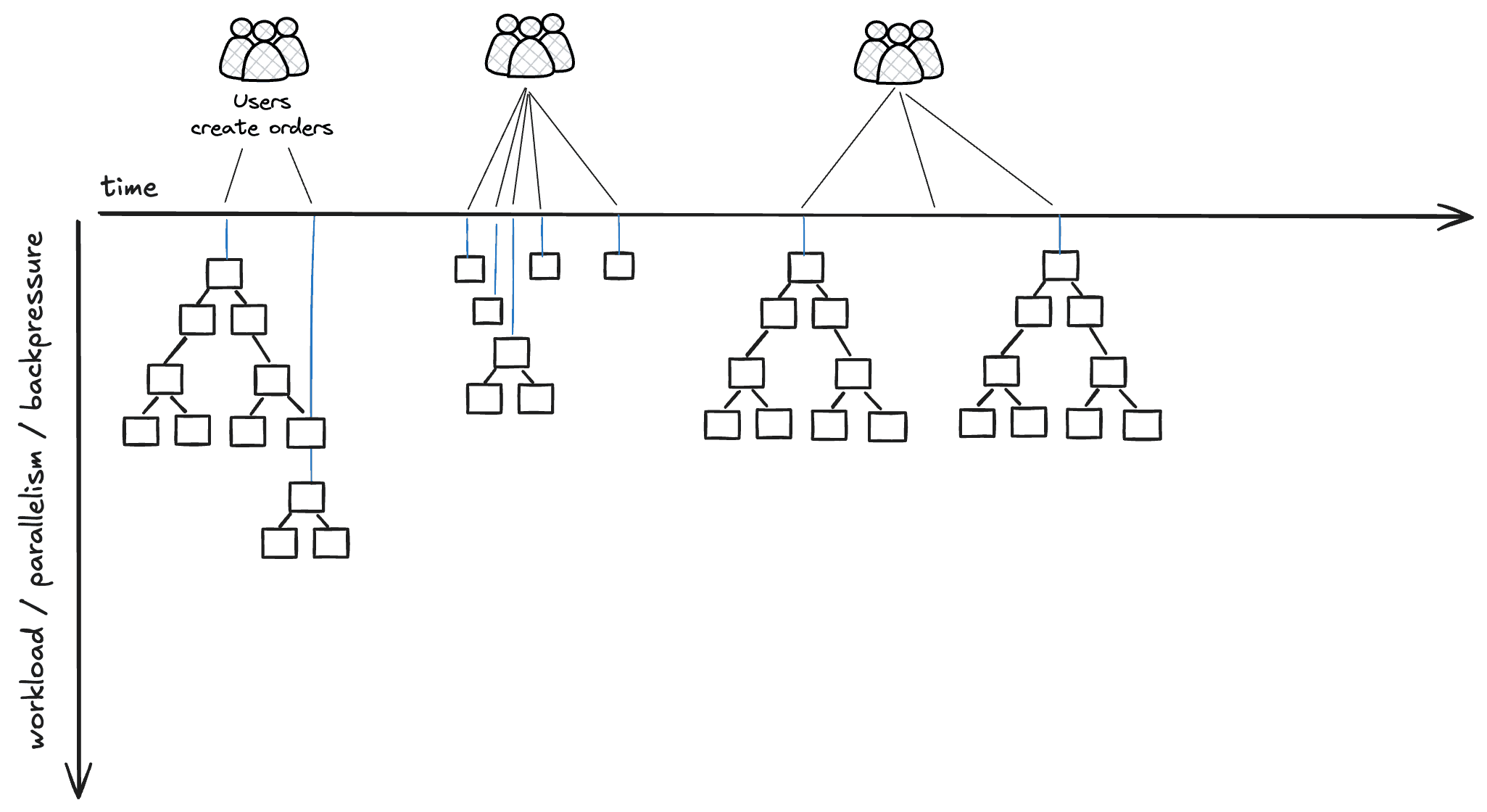
Empower your customers by allowing them to trigger asynchronous jobs directly from a customer portal or API. This is ideal for generating custom reports, visualizations, or performing exploratory processing of specific areas of interest.
Tilebox Highlights:
API-Driven Automation: Expose your processing capabilities directly to customers through a secure API, allowing them to request custom products on-demand.
Asynchronous Execution: Jobs run in the background, allowing your customer-facing portal or API to remain responsive. You can notify customers upon completion.
Secure by Design: The underlying architecture allows compute nodes to run in isolated environments without internet exposure, protecting your core infrastructure and algorithms.
What you’ll need:
A customer-facing application (e.g., web portal, mobile app) with an API.
Backend logic that translates customer requests into Tilebox API calls to submit jobs.
A scalable set of Task Runners to handle potentially bursty customer demand.
Next Steps:
Expose an API endpoint that your customers can use to trigger a Tilebox workflow.
Batch Workflows: Develop and Backtest Algorithms at Scale
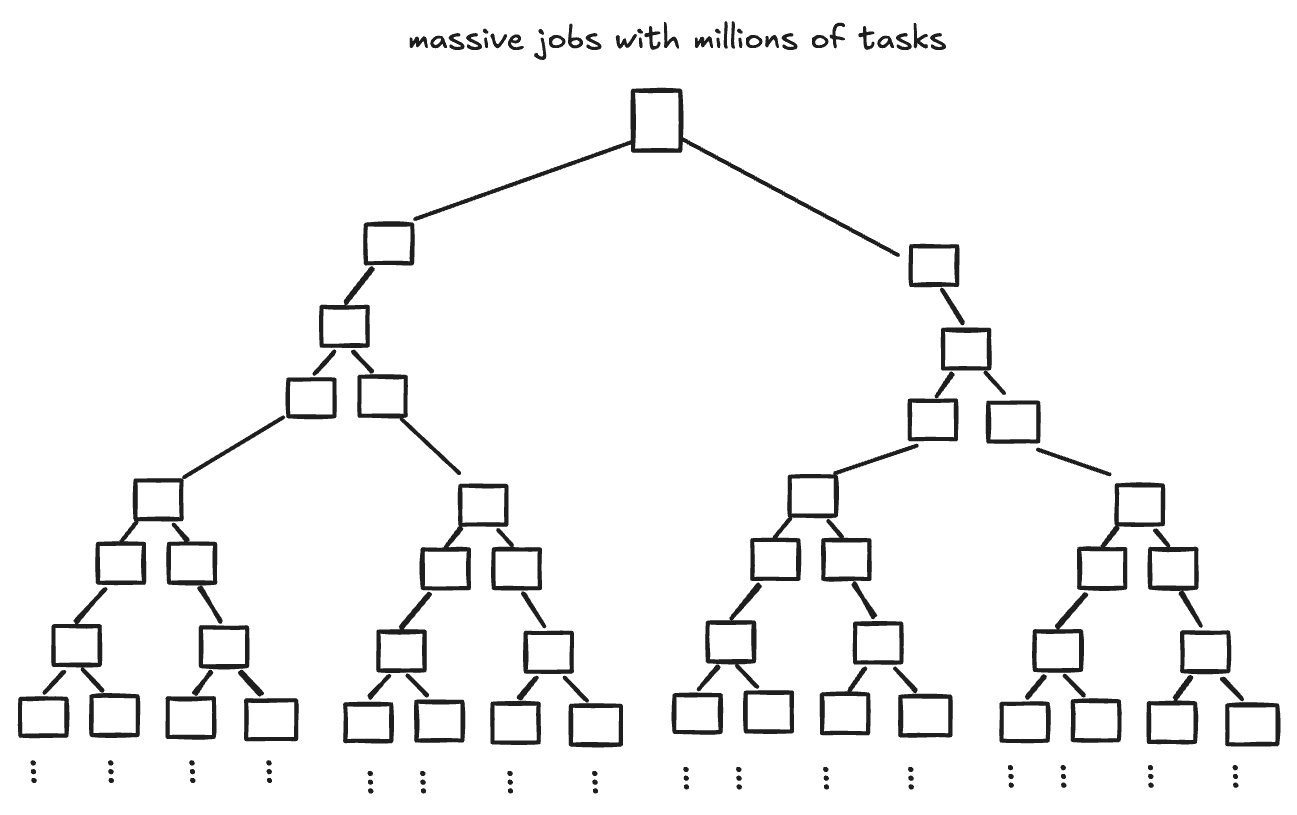
Batch processing is fundamental for developing and backtesting algorithms. It allows you to reprocess entire missions or apply new algorithms to large volumes of historical data, which is critical for creating and validating new products.
These workflows are ideal for large-scale processing that covers vast areas of interest or long time periods, such as creating quarterly cloud-free mosaics or running crop yield estimates.
Tilebox Highlights:
Dynamic Workflows: Unlike systems that use static DAGs, a Tilebox workflow can adapt at runtime. Tasks can determine subsequent steps based on intermediate results, enabling more complex and data-dependent processing.
Cost-Efficient Retries: For long-running processes, failures can be expensive. Tilebox allows workflows to be restarted from the point of failure after a bug is fixed, saving significant time and infrastructure costs.
Simplified Infrastructure: Tilebox simplifies deployment by not requiring complex cluster managers like Kubernetes. Since compute nodes operate independently without direct communication, network setup is significantly easier.
Flexibility and Scalability: Implement tasks in your preferred language—not just Python—and scale your jobs to handle millions of tasks.
What you’ll need:
An algorithm or processing logic defined in Tilebox Tasks.
A dataset to process (e.g., a large data archive or a custom Tilebox Dataset).
Compute infrastructure (even a local machine) to run a Tilebox Task Runner.
Next Steps:
Explore our workflows hello world to get started with your first batch workflow.
Scheduled Workflows: Automate Repetitive Tasks
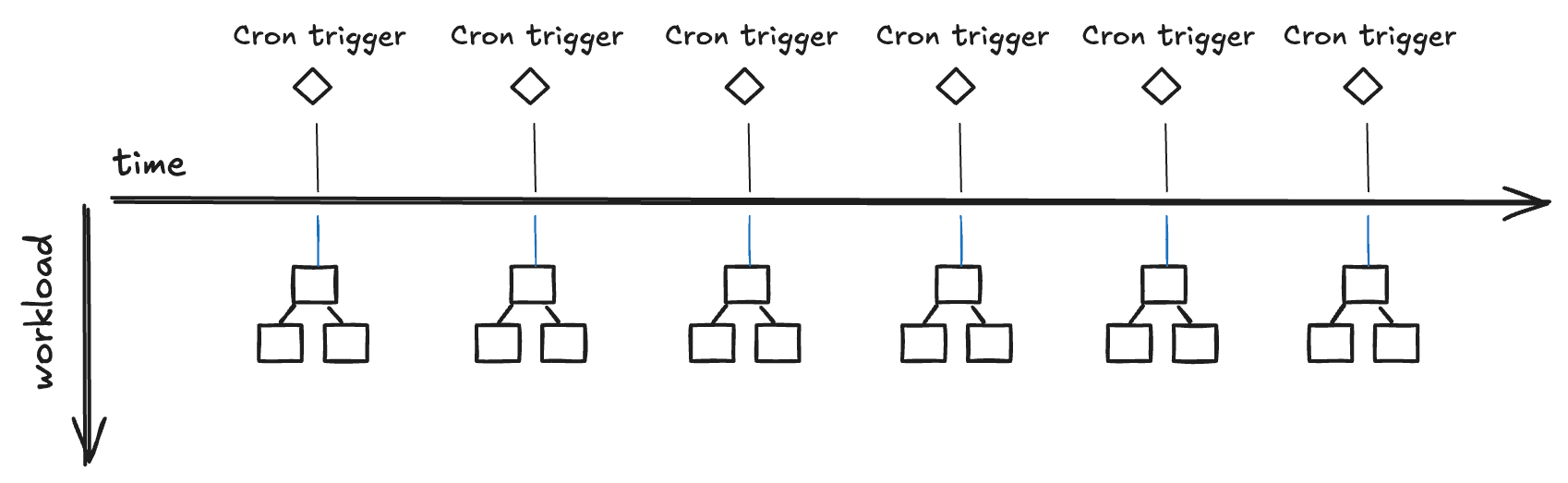
Automate recurring tasks to ensure consistency and reduce manual effort. This is perfect for operations that need to run at regular intervals, such as scraping tasks that operate hourly or workflows that generate daily mosaics and weekly reports.
Tilebox Highlights:
First-Class CRON Support: Scheduled automations are a core feature, allowing you to reliably run tasks at any interval.
Seamless Updates with Versioning: Deploy updated task logic at any time. The next scheduled run will automatically use the new version, enabling rolling updates to your jobs without downtime or manual changes.
Flexible Management: Manage your scheduled automations programmatically via the SDK or through the intuitive Tilebox Console.
Code Reusability: The framework for batch and scheduled workflows is the same, allowing for quick operationalization by reusing code between different modes.
What you’ll need:
A recurring task defined as a Tilebox Task (e.g., generating a daily report).
An automation configured with a CRON schedule in the Tilebox Console or via the SDK.
A continuously running Tilebox Task Runner to execute the scheduled jobs.
Next Steps:
See how to configure CRON triggers in the documentation.
Explore our CRON example on Github
Want to explore something else? Join us on Discord for community support, ideation, and more.

